※ replitで「You've used up all your Development time」というメッセージが出た人はこちらを参考にして新しくreplitのアカウントを作ってください。
※ 本題に入る前に、必ず動画の連絡 を見てください。
- 元画像の作成
(連絡, 課題1~4とは別動画です。連絡を見たら次にこちらを見てください)
(動画中でメニューが表示されていませんが、文字を描くためのペンは「カリグラフィ ペン」にしてください)
二値化
元画像がこのように白背景に黒の文字の画像だった場合、
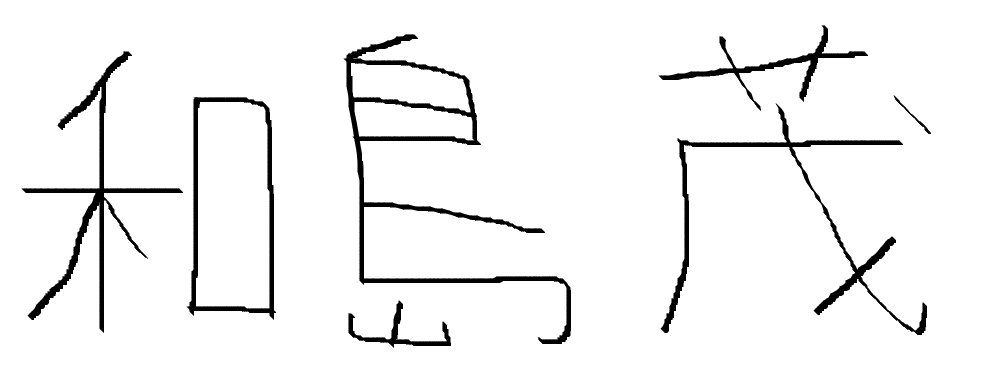
(画像形式が前回のようなモノクロビットマップでない限り) このように完全な白・完全な黒のどちらでもないピクセルが含まれる。

今回行う「細線化」では、処理前の画像にこのようなピクセルが含まれていてはいけないので、「完全な白」でないピクセルをすべて「完全な黒」に変える。
これは、まずグレースケール化処理
でRGBの成分が同じになるようにしたあとで、
で「明度が254より高いものは白、そうでないものは黒」にすることで実現できる。

二値化の第2引数は128とされることが多いが、ここでは「文字」にあたる部分をできるだけ広くしたいので、この引数を大きくすることで黒と判定される部分を多くした。
(課題1ではこの後に明度反転を行う。これは、次項の「細線化」の準備のため)
元画像がこのように白背景に黒の文字の画像だった場合、
(画像形式が前回のようなモノクロビットマップでない限り) このように完全な白・完全な黒のどちらでもないピクセルが含まれる。
今回行う「細線化」では、処理前の画像にこのようなピクセルが含まれていてはいけないので、「完全な白」でないピクセルをすべて「完全な黒」に変える。
これは、まずグレースケール化処理
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.threshold(image, 254, 255, cv2.THRESH_BINARY)[1]
二値化の第2引数は128とされることが多いが、ここでは「文字」にあたる部分をできるだけ広くしたいので、この引数を大きくすることで黒と判定される部分を多くした。
(課題1ではこの後に明度反転を行う。これは、次項の「細線化」の準備のため)
細線化
黒背景の中にある白いエリアで、「エリアの左上端のピクセル」「エリアの右下端のピクセル」「エリアの右上端のピクセル」「エリアの左下端のピクセル」を順に黒に変えると、最終的に幅1ピクセルの細い中心線が残る。

これを細線化といい、OpenCVでは
でそのような画像が得られる。
なお、この「thinning」というメソッドを実行するには、Shellで
のようにしてライブラリを読み込んでおく必要がある。

↓ (細線化)

例えば活字とこのような手書きの文字でも、書体が根本的に違っていなければ細線化したあとの線の枝分かれの構造 (トポロジー) が同じになるので、文書をスキャンした画像からテキストデータに変換するときなどに役立つ。
また、指紋の枝分かれのしかたも人によって異なるので、この技術が指紋の同一性の判定に使える。
黒背景の中にある白いエリアで、「エリアの左上端のピクセル」「エリアの右下端のピクセル」「エリアの右上端のピクセル」「エリアの左下端のピクセル」を順に黒に変えると、最終的に幅1ピクセルの細い中心線が残る。
これを細線化といい、OpenCVでは
cv2.ximgproc.thinning(image)
なお、この「thinning」というメソッドを実行するには、Shellで
pip install opencv-contrib-python
↓ (細線化)
例えば活字とこのような手書きの文字でも、書体が根本的に違っていなければ細線化したあとの線の枝分かれの構造 (トポロジー) が同じになるので、文書をスキャンした画像からテキストデータに変換するときなどに役立つ。
また、指紋の枝分かれのしかたも人によって異なるので、この技術が指紋の同一性の判定に使える。
ノイズによる細線化の失敗
文書をスキャンした際にノイズが含まれると

↓ (細線化)
白いエリアの中にある黒いノイズの周りが「ダマ」のようになって残るため、枝分かれの比較に使えなくなってしまう。
文書をスキャンした際にノイズが含まれると
↓ (細線化)
白いエリアの中にある黒いノイズの周りが「ダマ」のようになって残るため、枝分かれの比較に使えなくなってしまう。
膨張・収縮の組合せによるノイズ除去
オープニング (収縮→膨張)、クロージング (膨張→収縮) では白、黒のノイズが残ってしまうが、クロージング→収縮、つまり膨張→収縮→収縮 の順に処理を行えば白・黒両方のノイズを消せる。
ノイズ画像
↓ (膨張)
 黒いノイズが消える
黒いノイズが消える
↓ (収縮)
 白いノイズが小さくなる (クロージング画像)
白いノイズが小さくなる (クロージング画像)
↓ (収縮)
 白いノイズが消える
白いノイズが消える
この状態の文字の線は最初より一回り細い。さらに膨張処理を行えばほぼ元と同じ太さの線になるが、細線化の前処理としてはこの状態で十分。
これを元にして細線化を行えば、ノイズの影響を受けずに線の分岐のしかたを確認できる画像ができる。

オープニング (収縮→膨張)、クロージング (膨張→収縮) では白、黒のノイズが残ってしまうが、クロージング→収縮、つまり膨張→収縮→収縮 の順に処理を行えば白・黒両方のノイズを消せる。
ノイズ画像↓ (膨張)
黒いノイズが消える↓ (収縮)
白いノイズが小さくなる (クロージング画像)↓ (収縮)
白いノイズが消えるこの状態の文字の線は最初より一回り細い。さらに膨張処理を行えばほぼ元と同じ太さの線になるが、細線化の前処理としてはこの状態で十分。
これを元にして細線化を行えば、ノイズの影響を受けずに線の分岐のしかたを確認できる画像ができる。