動画の解説を参照
Wi-Fiの電波やLANケーブルで情報を伝えるときは、信号のON, OFFを素早く切り替えることで 0, 1の信号を送ります。
人間が使う a, b, c,...などの文字はそのままでは送れないので、例えば表1のように、一つの文字に
符号語を割り当てます。
このような表を決めるとき、符号語はどれも同じ長さ(
符号長)になるようにします。
送信者はもとの文の文字を一つずつ符号語に置き換え (
符号化)、それを信号として送ります。
受信者はその符号語の長さずつに区切って人間用の文字に置き換えれば元の文を得ることができます。
(これは簡単化した例です。実際は 1byte = 8bit (256種類) の符号語に対応させる「1バイト文字」、2byte = 16bit (65536種類) の符号語に対応させる「2バイト文字」があります)
情報通信の用語では、人間が使う a, b, c,...のような文字を
シンボル、符号化されたものの構成要素である 0, 1 を
符号アルファベットと呼びます。
表1
| 文字 |
符号語 |
符号長 (bit) |
| a |
00000 |
5 |
| b |
00001 |
5 |
| c |
00010 |
5 |
| d |
00011 |
5 |
| ︙ |
︙ |
5 |
| z |
11001 |
5 |
| 単語間スペース |
11010 |
5 |
| . (ピリオド) |
11011 |
5 |
参考 : モールス符号
19世紀から20世紀初めには、人間が使うアルファベット「a, b, c,...」を「•(トン)」「― (ツー)」の並びに置き換えて通信する、モールス符号が使われていました。
モールス符号で英文を送るには、
表2
| 文字 |
モールス符号 |
| a |
• ― |
| b |
― ••• |
| c |
― • ― • |
| ︙ |
︙ |
| h |
•••• |
| i |
•• |
| ︙ |
︙ |
| z |
― ― •• |
| . (ピリオド) |
• ― • ― • ― |
のような置き換えを行います (参考:
モールス符号 ‐
通信用語の基礎知識)。
さらに文字と文字の間には短い空白、単語と単語の間には長い空白を入れて区切ります。
その結果、どのような英文も「・」「―」「短い空白」「長い空白」の4種類の文字の並びに置き換えられます。
便宜上短い空白を「|」、長い空白を「‖」で表わすことにすると、例えば次のようになります。
this is a pen. → ―|••••|••|•••‖••|•••‖• ―‖• ― ― •|•|― •|• ― • ― • ―
これを受信した人は、|と‖で区切ってから表を逆に使って人間用の文字に置き換えて元の英文に戻します。
※ 現代的な通信では符号アルファベットが 0, 1 の2つであるのに対して、モールス符号では「・」「―」「|」「‖」の4つを使うので、モールス符号での符号化は4進数への変換であるとも言えます。
表1, 表2のような置き換えのルールのことを
符号 と呼びます
(「符号」という用語は符号化されたもの自体を表すことも多いですが、今回からしばらくは「置き換えのルール」を表すものとしてこの用語を使います)。
表1のような符号はすべての符号長が同じなので
等長符号、
表2のような符号はシンボルによって符号長が異なるので
非等長符号、と呼ばれます。
非等長符号は一見不便そうに見えますが、符号語の割り当て方を工夫すれば効率を上げられます。
話を簡単にするために、シンボルは a, i, u, e の4つだけで、文には単語間スペースもピリオドもないものとして、2つの例を考えてみましょう。
表3
| シンボル |
符号語 |
符号長(bit) |
| a |
00 |
2 |
| i |
01 |
2 |
| u |
10 |
2 |
| e |
11 |
2 |
表4
| シンボル |
符号語 |
符号長(bit) |
| a |
0 |
1 |
| i |
10 |
2 |
| u |
110 |
3 |
| e |
111 |
3 |
これらを使って例文を符号化してみます。
a, i, u, eが均等に使われている12文字の文「aaaiiiuuueee」は
表3の符号では 000000010101101010111111
表4の符号では 000101010110110110111111111
となります。全体の符号長は表3の符号では24bit, 表4の符号では27bitになります。この場合は表3の符号の方が短く情報を伝えられるので効率が良いということになります。
一方、aがそれ以外よりも多く使われる12文字の文「aaaaaaaaaiue」は
表3の符号では「000000000000000000011011」(24bit)
表4の符号では「00000000010110111」(17bit)
に符号化されます。全体の符号長は表3の符号では24bit, 表4の符号では17bitになります。この場合は表4の符号の方が効率が良いということになります。
この比較でわかるのは、表3の符号は単純に文字数で総符号長が決まるのに対し、表4の符号では文に使われているシンボルの割合によって効率の良さが変わるということです。
自分の姓名をローマ字で書いたものから a, i, u, e だけを抜き出し、それを表3と表4の方法で符号化したものの情報量を求めてください。導出過程も書いてください。
- 実際に符号化する必要はありません。それぞれの符号で a, i, u, e に対応する符号語が何bitであるかがわかっていれば十分です。
例
wajima shigeru から a, i, u, e だけを抜き出すと aiaieu となる。
表3の符号はどのシンボルに対応する符号語も2bitなので、これを符号化したものは 2 × 6 = 12 (bit)
表4の符号はそれぞれのシンボルに対応する符号語の長さを足して 1 + 2 + 1 + 2 + 3 + 3 = 12 (bit)
動画の解説を参照
英文では文字によって使われる頻度が異なります (参考:
英語アルファベット
- 文字の出現頻度 - わかりやすく解説 Weblio辞書)。
十分に長い文章であれば、「文字 a が発生する確率」,「文字 b が発生する確率」,「文字 c が発生する確率」, ... がそれぞれ決まった値になります。
つまり「文字を発生させる事象系」が1つずつシンボル (文字) を発生させて文を作っていると考えることができます。
\(
\begin{eqnarray}
X&&=
\begin{bmatrix}
x_a & x_b & \cdots & x_z \\
p_a & p_b & \cdots & p_z
\end{bmatrix}\\
&&=
\begin{bmatrix}
x_a & x_b & \cdots & x_z \\
0.0817 & 0.0149 & \cdots & 0.0007
\end{bmatrix}\\
\end{eqnarray}
\)
このような事象系を
情報源事象系といいます。
非等長符号でシンボル \(a\)~\(z\) に割り当てられる符号語の符号長をそれぞれ \(l_a\)~\(l_z\) とすると、一つのシンボルに対して割り当てられる符号長は平均で
\(L=\displaystyle \sum_i p_il_i\) (bit)
となります。この量を
平均符号長と呼びます。
平均符号長が小さいほど文全体を符号化したもののデータ量が小さくなり、効率の良い符号だということになります。
※ 準備 : 学籍番号を入れて「入力」をクリック (タップ) してください。
シンボルが a, i, u, e だけの場合に、それぞれが発生する確率が
\(p_a=\)
,
\(p_i=\)
,
\(p_u=\)
,
\(p_e=\)
であるときの、表4の場合の平均符号長を求めてください。計算過程も書いてください。
課題2解説
どの学籍番号の人の問題でも、\(p_a\) が0.15になるように設定しています。
対応する符号語の符号長が短い a が出にくいため、平均符号長は比較的大きめになり、効率の悪い符号になります。
シンボルが a, i, u, e だけの場合に、それぞれが発生する確率が
\(p_a=\)
,
\(p_i=\)
,
\(p_u=\)
,
\(p_e=\)
であるときの、表4の場合の平均符号長を求めてください。計算過程も書いてください。
課題3解説
どの学籍番号の人の問題でも、\(p_a\) が0.81になるように設定しています。
対応する符号語の符号長が短い a が出やすいため、平均符号長は比較的小さめになり、効率の良い符号になります。
動画の解説を参照
表で書くかわりに、符号を図の形で表したものを
符号の木と呼びます。
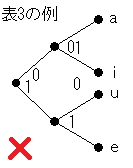
表3の符号の木は
のようになります。シンボルに対応する符号語は、黒丸 (
節点という) を結ぶ線 (
枝という)
に沿って書かれた符号アルファベットを左から順に読めば得られます。
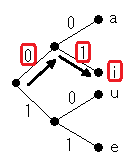
例えば i なら図のように見て「01」となります。
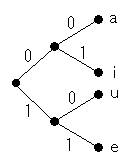
描き方の規則
- 左端から描き始める
- 節点から右に1本または2本の枝を出す
- それらの枝に沿って「0」「1」を書く
- 必要な分だけ分岐させる
- シンボルに対応する節点の隣にシンボルの文字を書く
表4の符号の木はこのようになります。
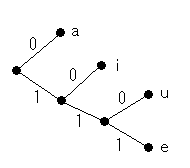
表3や表4の符号のように、右端以外のすべての節点から2本に枝分かれしている符号は
完全であるといいます。
一方、このような符号
表5
| シンボル |
符号語 |
| a |
1 |
| i |
01 |
| u |
001 |
| e |
0001 |
の木を描くとこのようになります。
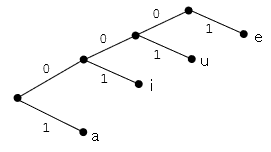
こちらは表3や表4と違い、2本に枝分かれせずに節点から右に1本だけの線が出ているところがある。このような符号を
不完全であるといいます。
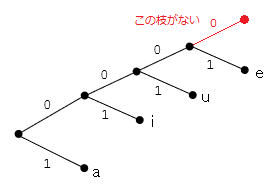
以下の符号に対応する符号の木を描いてください。
課題4解説
「0」「1」は接点ではなく枝に属するものです。接点の近くに書くのはNGです。枝の中央あたりに書いてください。
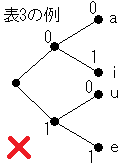
「0」「1」が枝分かれのどちらに属するのかがわかりにくくならないように注意してください。このような書き方はNGです。